@沉没2332
我也不太清楚是不是你具体想要的效果,总之先随便做了一个我理解中的效果:
主要是这三大步逻辑:
展开来分别是: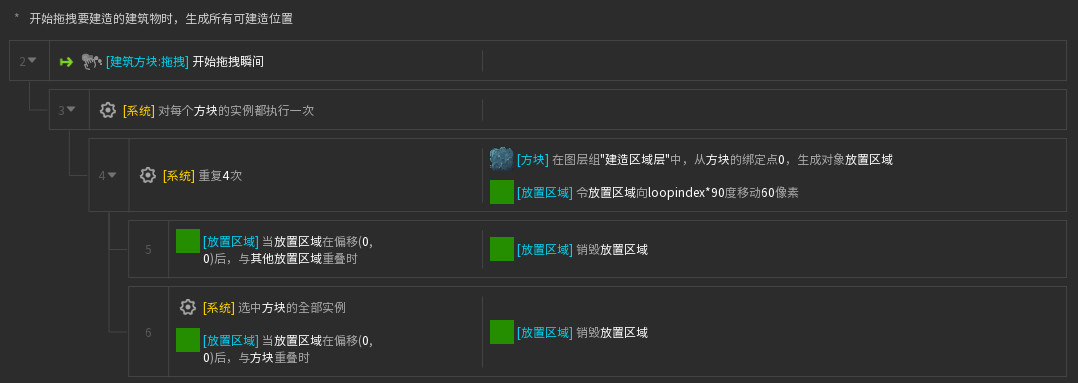
(第二点这里其实也不算主要的,就是高亮【放置区域】用的,不影响核心逻辑)

范例就放在这里了,主要是分享思路,实际得看具体项目:拖拽建造.evk
konoDIOda
@konoDIOda
23
声望
377
帖子
731
资料浏览
23
粉丝
0
关注
konoDIOda 发布的最佳帖子
-
分享自己关于2D俯视角游戏的图像深度管理思路发布在 综合讨论
做2D俯视角游戏的时候,不管是RPG、射击、ARPG,视觉上为了看起来自然,画面中的物体一般需要遵循下近上远的图像深度规则(越靠近画面下方,表示离镜头越近,层级越靠上,会盖住离镜头远的物体),但这个规则不像3D游戏,3D游戏是天然具有这个效果的,而2D游戏是需要靠自己用事件逻辑去造出这个效果的(这里指在唤境里)。


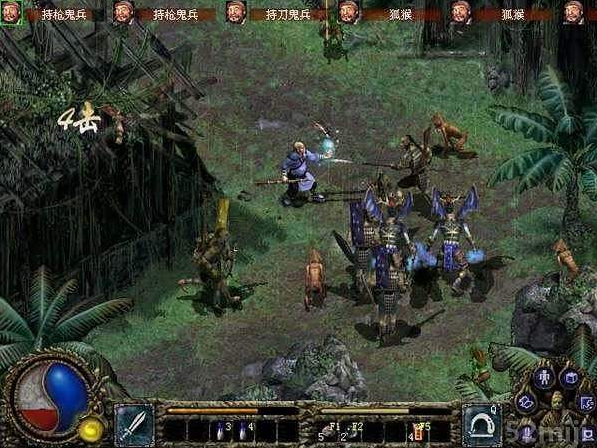
以上分别是RPG、射击、ARPG游戏的一些截图,可以看到都遵循了这一图像深度规则,而唤境也是提供了一个一键自动深度管理的基础功能的,不过效果比较有限,对于比较复杂的层级管理效果上比较有限。
自动深度管理功能的官方教程:https://www.evkworld.com/learn/350 官方的效果示意图:

从效果上看,大多数情况下其实已经足够用了,那是什么情况下会没法使用呢? 回到一开始说到的下近上远的图像深度规则,所谓的越靠近画面下方,转换为具体的依据就是图像的y坐标越大的意思,而自动深度管理功能的默认排序依据,也正是以此为准的(y坐标越大,层级越靠上,会挡住y坐标更小的图像),那么就有这么一个问题:假如我的人物整体构成是人物+武器这类由多部分图像共同组合的情况,这个自动深度管理功能还能发挥效果吗? 分两种情况讨论:- 绑定在人物身上的武器没有转动角度的需求时: 如果没有这种需求,通过修改武器图像的锚点到几乎跟人物锚点一致时(依据自动深度管理的依据,需要锚点的x坐标或y坐标略大于人物的锚点位置时才可行),才能勉强让这种复合型的图像构成,正常的参与到默认的自动深度管理功能中去,设置起来还是比较麻烦的。

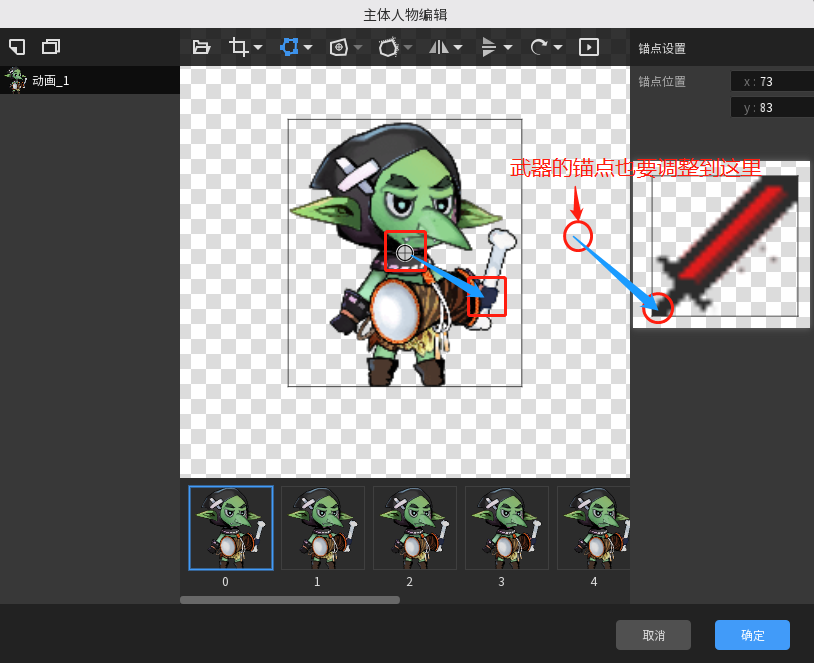
- 绑定在人物身上的武器有转动角度的需求时: 如果存在这种需求,显然上面的做法就没法使用了,因为图像的旋转是以锚点为圆心来进行旋转的,如果不把锚点设置在武器的握把处,旋转角度时就会变成像绕着人物的锚点转了(因为上述做法中人物和武器两者此时的锚点位置很靠近),而不是以武器握把处为圆心进行旋转。

可以看到效果很怪异的,正常情况应该是类似下面这样,武器是在人物的“手中”旋转才对。

但是如果照下面这样做,就会有一个新的问题,是关于深度管理中,图像锚点设置的合理性的。
深度管理中,图像锚点设置在哪个地方更具合理性? 关于这个,我们可以观察一下一开始那几个游戏截图。从透视的角度上看,仔细观察可以看到,物体底面的中心点作为锚点位置是比较合理的,对于人物来说也就是差不多在脚的位置上(或者说人物重心在地面上的垂直投影)。

为什么在这个位置是相对来说更具合理性的呢,你可以观察一下现实中,人站着时和物体的哪个面是处于同一个地面(平面)上的,是不是人的脚底和物体的底面,然后想象一下把视角移到头顶,判定人物和物体在这个地面(平面)的位置依据,是不是刚好就在人物和物体的重心处(例如下面这个纯俯视角的游戏)。
当然以上是基于现实情况来说的,而在引擎逻辑上,也有把锚点设置到该位置的合理性依据所在,那就是各种图像在尺寸上的差异,假如你的游戏设计中有一个巨大身形的boss,如果他的锚点也是默认的情况,那我方人物需要在boss的半个身体以上的位置,默认的自动深度管理效果下boss才能把我方人物挡住,过程中会出现下面这种人物好像飞起来一样的视觉效果,从视觉上显然是不合理的。
当然,你可以专门调整boss的锚点位置来解决这种情况,不过到目前为止,应该多少可以感受到为了使用默认的自动深度管理功能,做了多少标准上不统一的操作了,而这些徒增工作量的操作,其实反而让默认的自动深度管理功能变得束手束脚了。
自己动手做一个自动深度管理的功能如何? 上面我们已经分析了很多关于深度管理的特点,那么能不能利用这些特点来自己做一个自动深度管理的功能应对这种“人物与武器绑定”的复合图像的情况呢? 答案是可以的,但是具体好不好用,看各位自己的感觉,我这边只分享自己在这一块的思路: 把复合图像分为“主体”和“附着物”两个部分,主体部分参与主要的深度管理,附着物只跟它所绑定的实例执行层级排序,具体操作如下:
1、如上面所说,把这种复合式的图像分成“主体”和“附着物”两个部分,这里武器就是附着物(绑定物),人物本身就是主体(排序组)


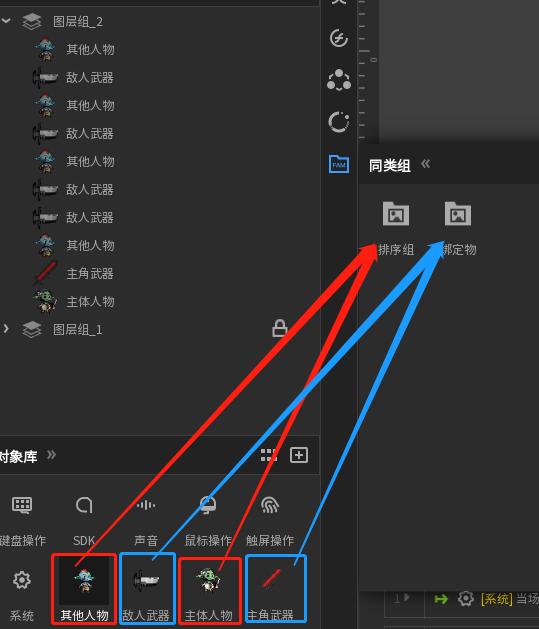
2、然后把“主体”和“附着物”进行关联,这里用了绑定能力来制造这种关联:
3、最后写深度排序的事件逻辑:
父事件部分:对每个“主体”以y坐标大小为执行次序分别执行一次事件,这里是按升序执行,也就是y坐标越小(越靠近画面上方,也就是离镜头越远的感觉)的越先执行,执行的内容是移到图层组顶部,这样的话当执行到后面的“主体”实例时,后面执行的会反过来盖在优先执行的实例的上面(就像把扑克牌一张张叠在一起一样,先放的肯定是在牌组下面),这样就完成了“主体”的排序逻辑。
子事件部分:在以上“主体”排序过程中,插入“附着物”对“主体”的排序,首先是选中当前正在遍历的“主体”所对应的“附着物”,然后这里因为武器是要显示在人物上面的,所以动作部分是将“附着物”移动到“主体”上方。

如此一来功能就完成了,效果如下,可以看到即使敌我双方都是有两个部分组成的复合型图像,也能作为一个整体参与到自动深度管理中:

范例工程:图像深度管理思路.evk 希望这篇思路分享能对正在制作俯视角游戏的朋友有帮助。
游戏制作过程中总是免不了遇到许多难题的,我们的前辈当年可能要克服的问题可以说只多不少(那时运行游戏的硬件性能不像我们如今这么好),这里安利一个2002年的国产游戏——《刀剑封魔录》,这款游戏在图像深度管理这块做到几乎可以说是极致的程度,详细可以看看这个视频中,关于这款游戏图像深度管理难度的相关解说: https://www.bilibili.com/video/BV1kK41177dW
-
RE: 优化建议 希望能完善关于对象实例选中方面的说明发布在 问题反馈
@creater 官网倒是有教程讲到这个,https://www.evkworld.com/wiki/321,不过【系统组件】里除了“选中实例”组之外的,就没有其他会筛选实例的条件了。然后每种对象的条件都具备筛选自身实例的效果,就这两个点

-
RE: 如何制作卡牌游戏电脑出牌的AI发布在 如何实现XXX功能?
炉石来举例也太硬核了
 ,我说一下自己的简单见解吧,卡牌游戏敌人AI的强弱取决于你对各个情况的出牌的优先级设计,这个情况的多寡又取决于你的卡牌规则,机制越复杂的卡牌游戏,AI需要应对的情况就越多。所以我从简单角度来看我个人倾向于仅设计AI的打牌“性格”,把行为模式分成几个类,再分别按AI的“性格”设计这些行为的优先级,例如把行为模式分成“进攻”和“自保”,“狂战性格”的AI就是无视自身生命值剩余多少,所有资源以减少对方生命值为主要目的来出牌,“稳健性格”的AI就是生命值高于一半时以进攻为主,反之以自保为主,“胆小性格”的则是始终以自保为主,自保达到一定程度才开始进攻这样。当然这个说法还是比较宽泛的,也只是一些大致方向上的个人见解,因为实际根据规则和牌库,设计的细节上也会很复杂,感觉专门找一下一些专业的游戏设计的教程或视频看看会比较好。
,我说一下自己的简单见解吧,卡牌游戏敌人AI的强弱取决于你对各个情况的出牌的优先级设计,这个情况的多寡又取决于你的卡牌规则,机制越复杂的卡牌游戏,AI需要应对的情况就越多。所以我从简单角度来看我个人倾向于仅设计AI的打牌“性格”,把行为模式分成几个类,再分别按AI的“性格”设计这些行为的优先级,例如把行为模式分成“进攻”和“自保”,“狂战性格”的AI就是无视自身生命值剩余多少,所有资源以减少对方生命值为主要目的来出牌,“稳健性格”的AI就是生命值高于一半时以进攻为主,反之以自保为主,“胆小性格”的则是始终以自保为主,自保达到一定程度才开始进攻这样。当然这个说法还是比较宽泛的,也只是一些大致方向上的个人见解,因为实际根据规则和牌库,设计的细节上也会很复杂,感觉专门找一下一些专业的游戏设计的教程或视频看看会比较好。
-
设计思路分享——设计游戏新手教程的建议发布在 综合讨论
这篇建议来自于一位西班牙的游戏设计师——Carlos Valenzuela, 他分享了6点关于“怎样为游戏设计新手教程”的建议: 1、玩家讨厌被教导,而游戏作为一天工作/学习后的一种放松方式,如果玩一个游戏还要被一板一眼看教学的话,劝退的概率是很大的,所以不应该过于直接地教玩家如何玩游戏,你需要尽可能为玩家设计出一种能边玩边学的游戏体验。
2、提供流畅的游戏体验,尝试引导玩家进入“心流”的状态,为玩家提供一个循序渐进的难度阶梯,并且在过程中为玩家提供明确的目标、即时的反馈和满足感。 (“心流”的概念是心理学家米哈里·契克森米哈赖提出的,指当一个人进入心流状态时,会完全专注于自己正在做的事情,不会被周围环境分散注意力。
 )
)3、不同玩家有着不同的学习风格和习惯,所有人获取信息的方法总有差异。基于VARK学习模型,可以将学习者划分成视觉、听觉、动手尝试、社交等四个不同的类型,开发者设计新手教程时可以多多思考这几类学习者的需求,利用图像、音频反馈以及允许试错等方式来鼓励玩家学习游戏规则。
4、平衡游戏体验,益智手游《Threes》的开发者阿瑟·沃默尔曾解释说,每款游戏的新手教程都需要实现四个目标:
-
为玩家营造舒适感。避免用不必要的元素打扰玩家学习,应允许玩家自由尝试和练习。不要在屏幕上堆满玩家不了解,或者暂时还不需要了解的东西。
-
让玩家感到兴奋,向他们展示玩法的各种可能性。也许玩家正在挥舞木棍练习,但可以暗示他们,今后还有可能会与巨龙搏斗。
-
尊重玩家,不要像对待机器人那样对待玩家,向他们发送指令或要求。
-
让玩家明确游戏的规则、玩法、游玩目标等内容。
这几个目标存在一定的彼此矛盾,所以开发者需要平衡它们的比重,既不适合让玩家在新手教程阶段漫无目的地自由游玩,又不能以命令的方式要求玩家做事情。
5、利用游戏机制来解释另一个游戏机制,例如,我们想让玩家知道墙的背后有隐藏的宝藏,但玩家首先得将墙摧毁。该怎么做呢?我们不宜采用含有大段文本的弹出窗口来向玩家解释,也无需采用某个发光的符号或箭,它们都不属于玩法机制……如果玩家可以攻击,那就让他攻击。我们可以在墙的正前方放置一个敌人——当敌人被击倒后,墙也会被撞毁,这样一来玩家就可以看到墙背后的隐藏宝藏了。
6、一些其他的提示
-
玩家不喜欢在游戏里阅读文字,所以开发者应当尽量控制文本量。
-
避免使用俗气图像,或发光的手指、移动的箭头等“引导”元素,因为那会导致玩家对游戏的印象分大减。
-
在游戏菜单中加入“信息”按钮,确保玩家随时可以查看新手教程。
-
随着挑战难度的上升,游戏应当让玩家觉得越来越有趣,维持对游戏的兴奋感。
(内容有缩略,关于本文的译文搜索“怎样为游戏设计新手教程?海外开发者分享了6点建议”应该就能找到了)
-
-
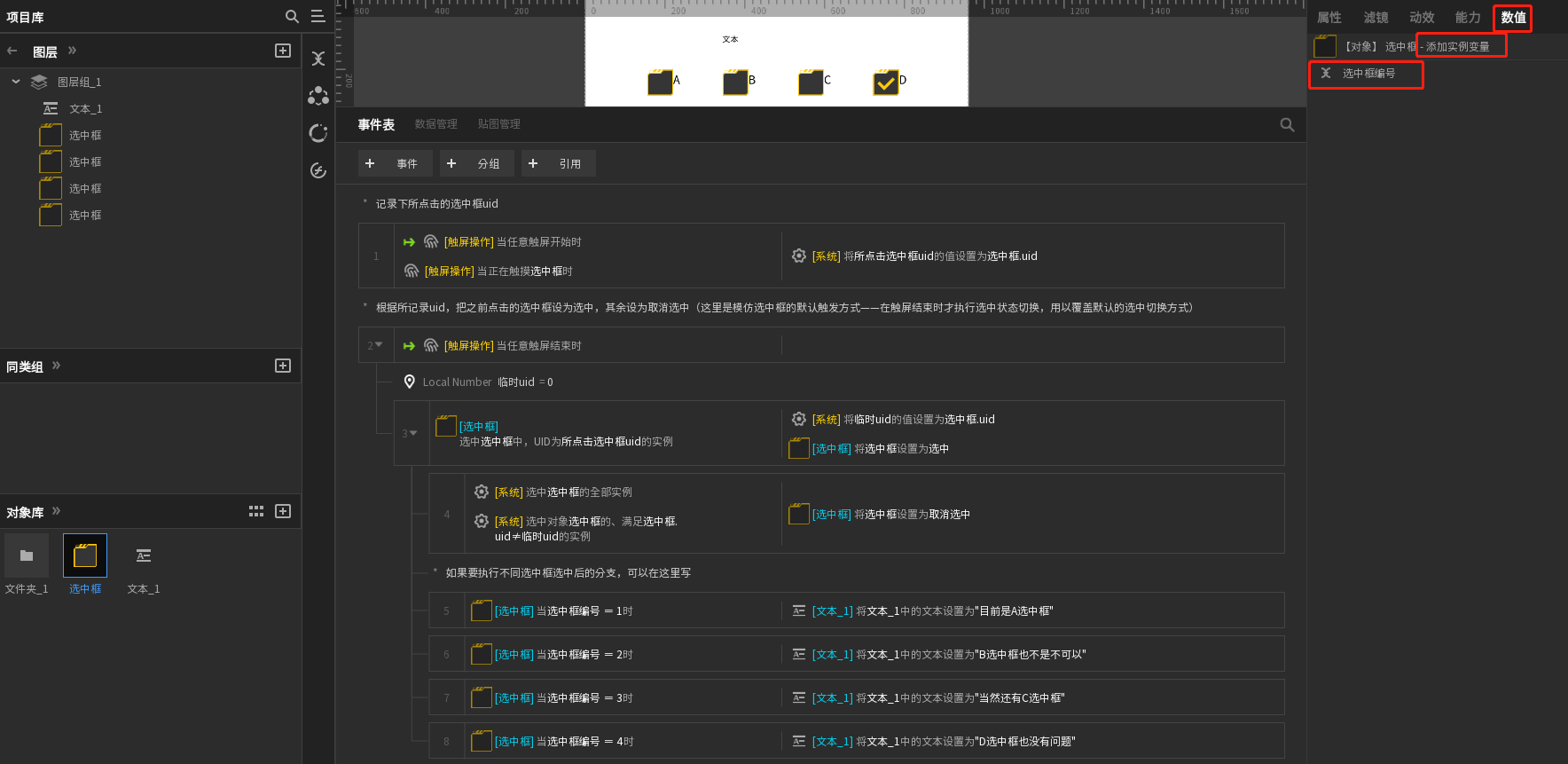
RE: 如何实现选择框只能选择一个,且必须选择一个?发布在 如何实现XXX功能?
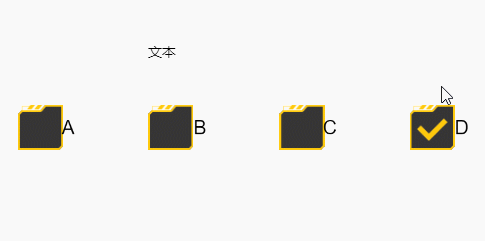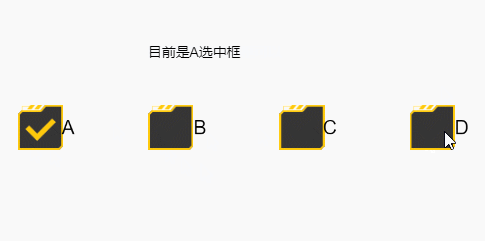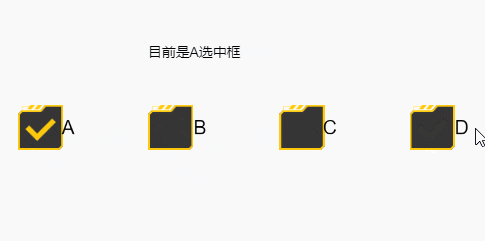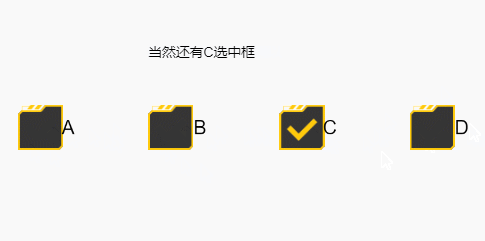
你说的那个方法有疏漏,如果操作的人执行了长按移开后再松开的操作,就会触发不了,如下:
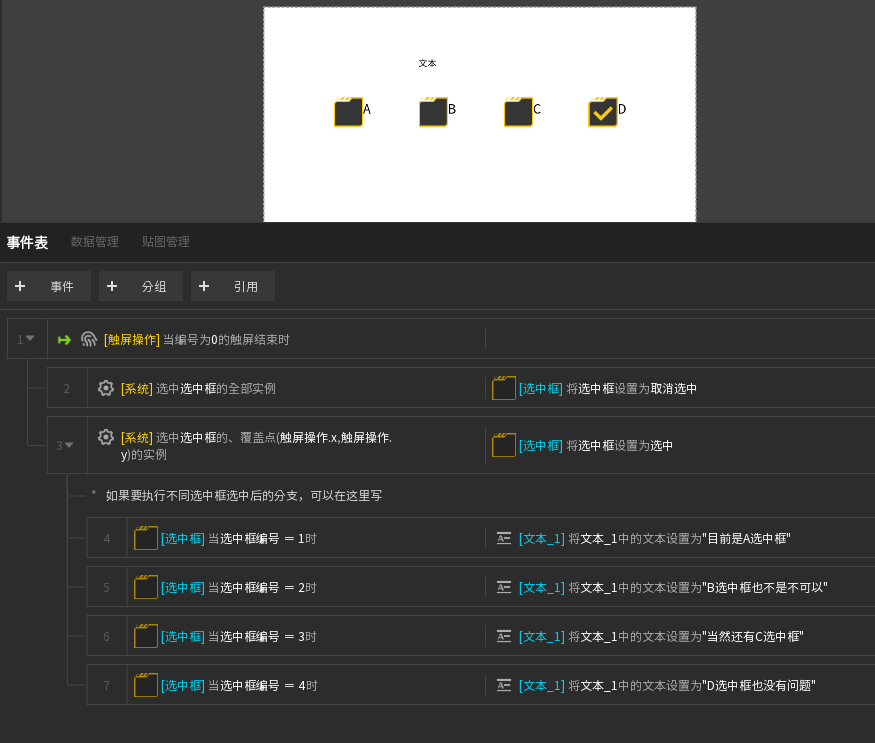
结果如下,会出现没有必选一个的情况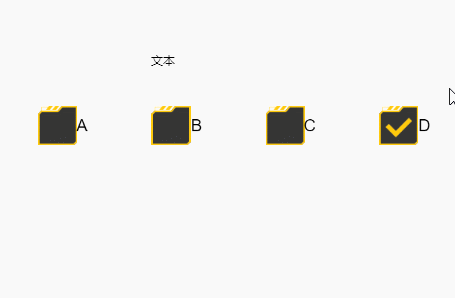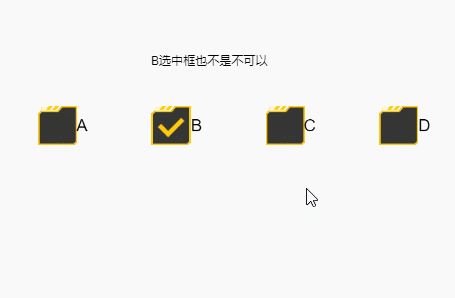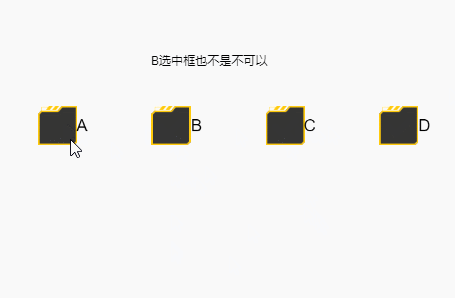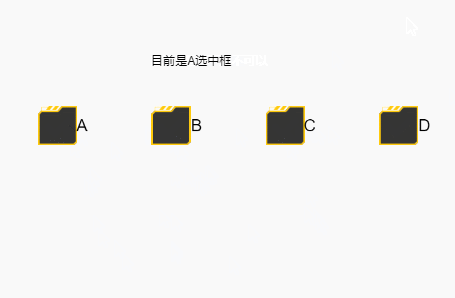
简单来说,就是选中框的默认状态切换方式,是按下时按在选中框,然后无论在哪里抬起时,都会触发这次状态切换,如果你写的事件没有覆盖这个操作的话,就会被这个默认的方式干扰导致以上情况
如果不用选中框组件,而是自己用精灵自制选中框效果的话,你说的方法就很好用
-
RE: 设计思路分享——设计游戏新手教程的建议发布在 综合讨论
之所以想分享这篇文章,其实也是想给论坛里正在制作游戏的各位一个思路指引,目前已经能看到不少唤境使用者的优秀作品了,包括在官方群里,也常常能看到各位发自己的游戏测试链接,但是也常常听到试玩者发出这么一个疑问:“这个游戏怎么玩?”。因为作为制作者,其实是对游戏机制(或者说游戏玩法)了若指掌的,所以会比较容易忽略新手教程的重要性,甚至可能偷懒直接弄一大串文本让玩家看,不排除有愿意逐字逐句读这些说明文本的玩家,但不可否认的是确实容易让人第一印象变差。 关于上面分享的这篇文章,我个人的看法是:作为游戏制作的兴趣爱好者或者游戏制作的入门从业者,上面提到的建议不一定硬要全部做到,还是根据自己的情况取自己觉得可行的有帮助的几点来做就好,毕竟不同的游戏类型适用的点也不一样,强行做到以上内容可能会适得其反,所以主要还是纯粹分享这个设计新手教程的思路,希望各位早日完成自己的游戏作品。
-
RE: 求一个华容道小游戏的制作思路发布在 新人提问
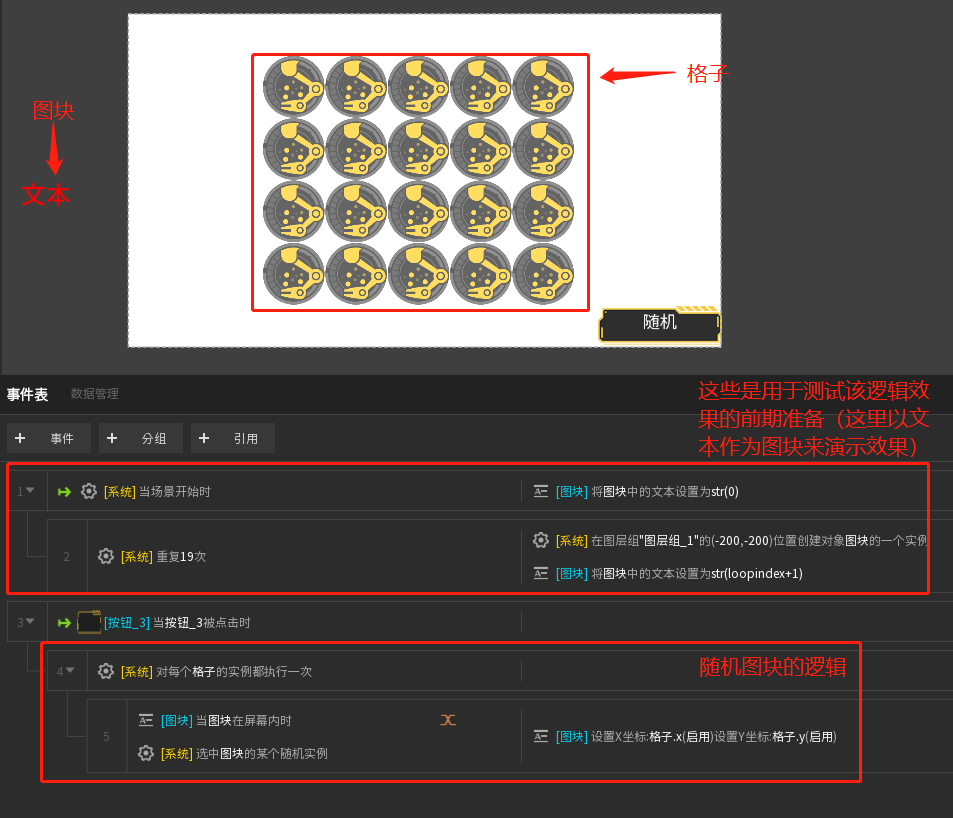
对于1:方法算是挺多的,但是复杂程度有高有低,我想到的主要有两种方法 ①(因为需要掌握数组组件,相对较难)通过数组+随机数来生成一组次序被打乱的序号组,根据这个打乱后的序号组,在格子上依次生成对应编号的拼图块。 ②(相对简单,但是比较繁琐)把拼图块和格子在舞台上摆好,拼图块先摆在屏幕外,格子用实例笔刷刷好,
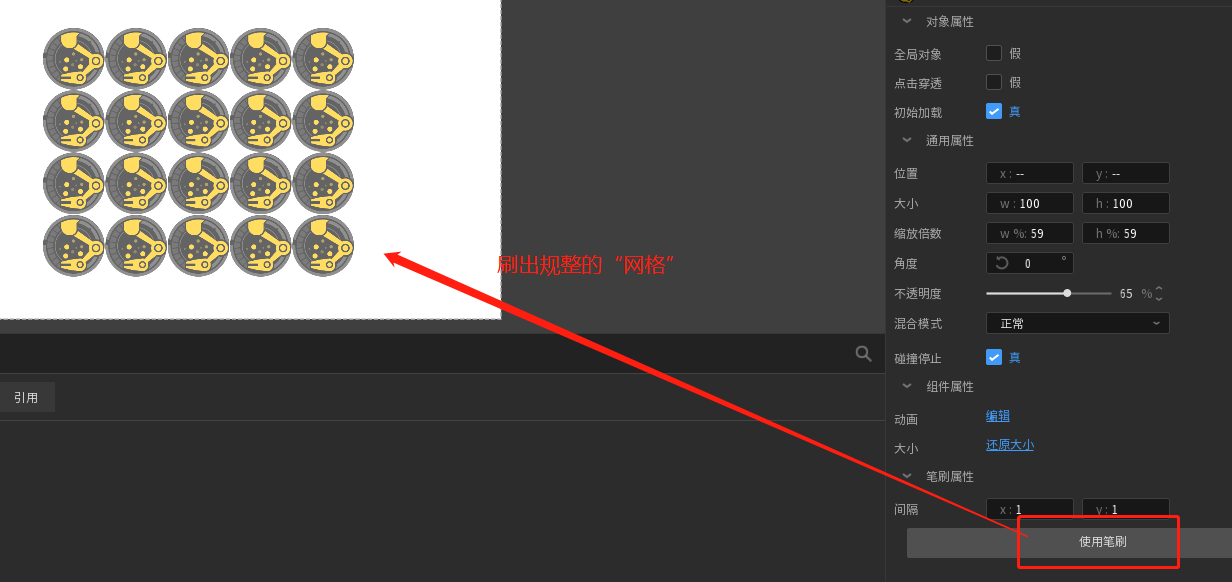 然后对每一个格子实例,在“不在屏幕内的拼图块”中随机一个实例,把随机到的拼图块位置设置到当前的格子实例上去。
然后对每一个格子实例,在“不在屏幕内的拼图块”中随机一个实例,把随机到的拼图块位置设置到当前的格子实例上去。
 效果预览(可以看到两次的随机结果是不一样的):
效果预览(可以看到两次的随机结果是不一样的):

对于2:这个会涉及两个图块的选中,方法也是挺多的,比较直观的是比较位置,选中第一个图块后,用变量记录下第一个图块的位置,然后选中第二个图块时,也是如此,之后判断它和之前的图块的位置差异([两者x相同,两者y的差值为一个纵向的格子间隔距离],[两者y相同,两者x的差值为一个横向的格子间隔距离],这些情况只要满足其一即表示为相邻),然后彼此设置位置为对方的位置,即完成交换。不过这个免不了要理解“实例选择”的机制,这里只提供思路。
对于3:判断拼图是否已完成,其实就是完成“判断所有的图块是否都已在对应格子”这件事,给拼图块和格子一个相对应的编号(例如20个格子,它们的编号分别是1,2,3……,正确的拼图块排序也是这样,编号分别为1,2,3……),先把计数用的变量设置为0,对于每一拼图块,当它的编号与重叠中的格子的编号相同时,计数用变量的值+1,最后计数用变量的值跟格子数量相同时,表示都摆放正确,则拼图已完成。官方的模板里好像也有一个拼图模板,你也可以看看里面是怎么判断拼图已完成的。
konoDIOda 发布的最新帖子
-
RE: 【优化建议】输入框有个"组件属性.开始可见"就方便多了发布在 问题反馈
@大红裤头欢乐多 是否开始可见是实例的属性不是对象的,从对象库选的话应该会看不到,你选一下舞台上的输入框实例看看,我记得应该是所有可视组件都有这个属性的才对

-
RE: 精灵碰撞问题发布在 训练营
@baiduren123 你在编辑器的场景属性栏里,应该可以看到一个叫“显示碰撞区”的选项,这个只在编辑器内生效,你可以看看两个精灵的碰撞区域是怎样的。“碰撞”这个条件的触发就是两者的碰撞区域从不重叠变为重叠的一瞬间触发。如果你发现开了显示碰撞区,然后实际预览时碰撞的触发还是跟你看到的碰撞区位置差别很大,还有可能是不同动画帧的碰撞区域设置上是不同的,碰撞是以当前动画帧的碰撞区域为准去判断是否触发的。所以这几点查查就能排出可能的原因了。
-
RE: 【FAQ】怎么使用数组读取json的文档发布在 FAQ
@白茶两碗 没有一个大的根目录,唤境的xml需要有个最大的标签包裹在最外面,例如
<A>啊</A>
<A>哦</A>
这样直接去读取第二个A标签的内容的话,会读取不到,需要是类似下面这样,有个最大的标签包括,才能读取到第二个A标签的内容
<Z>
<A>啊</A>
<A>哦</A>
</Z>
我比较好奇的是,你这个xml是怎么来的,应该是什么软件转换来的而不是自己手写的吧,因为只从唤境的这个xml使用来讲的话,有好多无关信息。
-
RE: 关于数组组件快速导入数据发布在 训练营
@白茶两碗 数组不是有导入csv的功能了吗,“从字符串读取”这个动作基本上就是直接或间接填 数组的asjson这个表达式,从而达到“读取其他数组的数据”或者“读取这个数组之前暂存到其他位置的数据”的目的。例如你在10分钟前,把某个字符型变量A设置值为A数组.asjson,然后这十分钟内A数组的数据变了很多,现在你想把A数组读取回十分钟前那个数据,就可以用“从字符串读取”,然后填那个变量A上去。或者有A和B两个数据不一样的数组,现在你想让A数组的数据变得跟B数组一样,A数组就可以用“从字符串读取”的动作,然后填B数组.asjson就行。(其实这个问题都两年前了,回复对不上也正常)
-
RE: 唤境有好多功能没有 期待引擎开源发布在 综合讨论
@小沙盒工作室 其实我觉得唤境面向的主要人群还是更倾向奔着免编程来的小白一点的,不然不会迟迟不出代码模式,更功利点来说,可能有他们的商业考量在,毕竟只要涉及到公司的生存问题,代入去想我就觉得目前这样也不奇怪了,可能你的期待也会大概率落空?
-
RE: 【BUG反馈】被禁用的逻辑会中断从上到下的逻辑执行过程发布在 问题反馈
@只玩人族无敌 “否则”的效果必须是上面一条事件有产生判断且判断的结果为条件不成立,禁用就相当于没有判断,所以就直接不运行了,然后因为一个否则不运行,后面的否则也就跟着不运行了
-
RE: 【BUG反馈】场景改名后逻辑中的跳转场景动作失效发布在 问题反馈
@只玩人族无敌 变量名、对象名基本都不支持动态输入的,但场景可以,你可以找找看,变量名不存在从其他变量的值中获取然后让它作为被操作的变量去操作它的值,对象名也是如此(对象名除了唯一一个“按名称创建实例”这个动作是允许用动态输入的),它们两个都必须要自己“手动”选中才能被操作,但场景名那里可以直接从单选框切成输入框,然后通过字符拼接的方式动态输入场景名,例如我有“关卡_1”、“关卡_2”、“关卡_3”……到“关卡_50”好了,那我只需要获取某个变量值,然后跟“关卡_”这个前缀拼接,就能让单条跳转场景事件有动态的场景跳转效果,例如我按下某个按钮,按钮上有数字表示它是第几关,那我只需要获取这个数字并拼接这个关卡前缀,就不需要写50个场景跳转事件了,只要一个就通用,这种动态跳转场景的情况下,如果我修改场景名,事件里又该怎么跟着变呢?
所以我觉得目前这样是合理的,如果你还是坚持自己的看法的话,我感觉有点像最开始那样,跳转场景最开始是两个动作的,“跳转场景”和“动态跳转场景”,以前的纯“跳转场景”动作确实是会跟着变的,但也是有人提议过要改,因为以前有人制作到一半觉得自己场景跳转的事件太冗杂了,想换个跳转场景的写法,结果都得删掉都换成“动态跳转场景”动作,我想目前这个状态可能是官方做的一个折中方案吧。
或许你可以把这个作为一个优化建议来提,例如单选框状态下会跟着变,切换成输入框就不跟着变了之类的,但我个人来看还是坚持自己的观点,这个确实不是bug,顶多是个用户体验还无法完全满足不同人需求的设计,而目前这个设计,确实也给纯粹使用单选框来跳转场景的用户带来了不便利性,是个能进一步优化的点。
 ,感谢分享
,感谢分享